![]()
![]()

Data mining is the extraction of knowledge from data. More specifically, it is the process of accumulating and learning patterns and rules in a large-scale database, thus forming a 'knowledgebase, from which new knowledge can be discovered and learned. Data mining is also known as 'Knowledge Discovery in Databases', or KDD.
To handle a large-scale database, two major issues must first be addressed. The first is data quantity; the second, data quality. The issue of data quantity arises as there is an enormous volume of data to be processed, necessitating techniques for efficient data processing. Moreover, as human beings have a limited capacity to comprehend such large volumes of data, it is necessary to develop a mode of data expression recognizable to a human being.
The issue of data quality occurs as a result of the attributes of and complicated relations among the extensive data. Although one can ascribe patterns or rules to attributes and data, because the relationships are so complicated, there is a near infinite number of possible combinations, of which only a limited set will contain meaning. As it is impossible to verify every combination, an approximation method that improves processing efficiency and renders the problem tractable is required. Furthermore, it is difficult for a human being to extract meaning from patterns discovered in data if they are overly complex. Consequently, for people to be able to recognize and assign meaning to the patterns, it is necessary to develop a suitable form in which to express them.
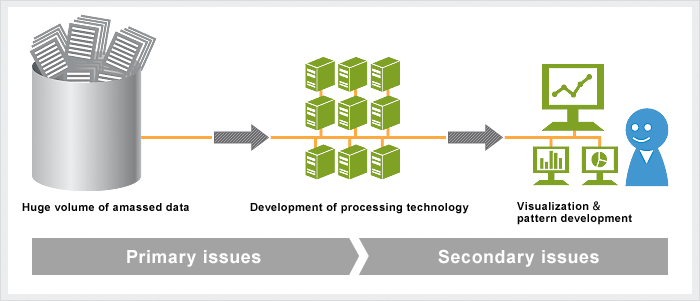
Data mining is shouldered with the task of solving problems inherent in handling large-scale databases. In short, it faces the task of solving problems like upper levels of processing efficiency and the limit of human recognition power, which occur as the scale and complexity of the data increase. Technical approaches in data mining look to develop methods that achieve both efficiency and efficacy in analysis of a large-scale database.
1.Knowledge Representation
Knowledge representation is the creation of a framework that transforms, in line with a given objective, a large amount of complex data into a particular form of data or procedure that human beings can comprehend. Data mining is the process of transforming vast quantities of data into a certain form of knowledge representation to which a human being can assign meaning, and one of the important domains of data mining is to develop such knowledge representation in line with a certain objective. For example, one type of knowledge representation is called a 'decision tree'. A decision tree is a framework for classification of a large amount of data. The results of judgments regarding conditions are displayed as branches, and data is rendered in its entirety as a tree structure. Fukuda, Morimoto, Morishita and Tokuyama (1996) have had success in visualizing voluminous data by expressing data distribution using color. This kind of knowledge representation makes it possible for people to express their knowledge in a straightforward manner (Anzai, 1989), and thus plays an important role in both development of extant knowledge and knowledge discovery.
2.Evaluation Criteria
To discover new and interesting patterns and rules within large data sets effectively, criteria with which to evaluate such findings must be established. Within a given database, there will be a large number of patterns and rules. It would be extremely difficult for a human being to evaluate each of these from every conceivable angle. By establishing simple criteria for estimation, evaluation of the patterns and rules can be carried out by a computer. When a human being then selects and evaluates favorable results from the computer-driven evaluation, it becomes possible to efficiently discover beneficial patterns and rules (Matheus, Chan, and Piatetsky-Shapiro, 1993).
As an example of evaluation criteria, let us examine 'confidence' and 'support' of 'association rules' (Agrawal, Imielinski and Swami, 1993).An association rule states that a certain condition A necessitates a phenomenon B. An example of such a pattern or rule would be a high probability that women in their 30s who often purchase a cheeseburger with an apple pie also buy 100 or more diapers at the same time. To show the plausibility of such patterns and rules, 'confidence' and 'support' can be used as evaluation criteria. The 'confidence' indicates the proportion of the data, which fills condition A and also causes phenomenon B. By examining the confidence, the probability of a given pattern occurring can be evaluated. However, even when a pattern appears to be certain, it is not possible to determine its significance right away, as the data that fulfills condition A may represent an insignificant fraction of the entire data set. The 'support' indicates the proportion of the entire data set in which phenomenon B occurs when condition A is fulfilled. This makes it possible to evaluate the importance of the discovered pattern in light of the entire data set.
3.Algorithms
To process large-scale data effectively according to analysis objectives, it is imperative to develop suitable algorithms. Furthermore, when the size of the data set increases, the importance of the algorithm increases in tandem. For example, when considering combinations of 2 items, each of which can have 1 of 10 varieties, there will be 10 to the power of 2 combinations, thus 100 possible combinations. With 1000 varieties, there will be one million possible combinations, and with three items one billion, and so on exponentially with each extra item. In the business world, it is likely that the efficiency of computer-driven processing of large-scale data will be an increasingly pressing problem in future years.
As there are so many viable approaches, useful results can best be achieved by bringing together researchers from different backgrounds who are capable of tackling a given problem from different perspectives. The DMLab is lucky enough to have such a team, and is committed to producing practical and useful strategic applications for large-scale data.