データマイニング(Data Mining、データからの知識発掘)とは、大規模なデータベースから発見されたパターンやルールを知識ベースとして蓄積・学習し、新しい知識を発見・学習するプロセスである。データマイニングシステムとは、このような知識をデータベースから発掘する知識獲得システムであり、これらの獲得された知識を知識ベースとしてコンピュータ内外に蓄積している。またそれは、人間の介在を最小限に抑えながら、新たな知識の生成を達成しようとするものである。データマイニングは、ナレッジ・ディスカバリー・イン・データベース(Knowledge Discovery in Database)、略してKDDと呼ばれることもある。
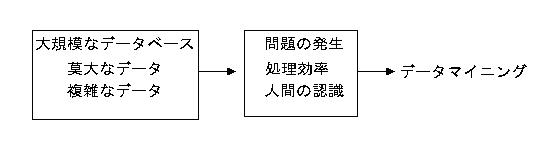
大規模なデータベースを扱うためには、2つの重要な問題を解決しなければならない。第1の問題はデータの量的な問題であり、第2の問題はデータの質的な問題である。以下で図2にそって説明していこう。第1のデータの量的な問題とは、社内に蓄積されているデータ量が莫大になりすぎて生じる問題である。例えば事例1、2で紹介したファルマという企業では年間の販売データだけで60ギガバイトを越えており、それを処理するには処理効率を向上させる技術的手法が開発されなければならない。また、そうした莫大なデータを人間の能力ではすべてを把握することはできないために、人間が認識できる何らかの表現形態を開発する必要もある。
第2のデータの質的な問題とは莫大なデータ内の属性、またはデータ間に複雑な関係が存在することから生じる問題である。属性間、またはデータ間でのパターンや規則性といっても、その関係が複雑なために組み合わせだけでも無限に近い組み合わせが存在することになる。それらすべてを検証していくことは不可能であるため、近似的に求め処理効率を向上させるやり方などが必要になる。また、発見されたデータ間のパターンが複雑すぎると、人間がそこから意味を見つけだすことは困難になる。こうした意味でも、人間が認識でき、意味を付与することのできる表現形態を開発する必要がある。データマイニングは、大規模なデータベースを扱うことから生じる問題を解決するという課題を背負っている。つまり、データの規模や複雑性が大きくなることによって生じる処理効率や人間の認識力の限界などの問題をクリアすることが求められているのである。データマイニングにおける技術的アプローチとは、こうした大規模なデータベースを用いた分析における効率性と有効性の両者を達成しようとする技術的な方法を開発しようとするものである。
例えば、決定木(decision tree)と呼ばれる知識表現がある。これは大量のデータ群を分類するとき、条件判断の結果を部分木として表し、データ群全体をツリー構造で表現する枠組みのことである(図3を参照)。また、Fukuda, Morimoto, Morishita and Tokuyama (1996)は色を使ってデータの分布を表現し、大量データをビジュアライズ化することに成功している。こうした知識表現は、結果的に人間のもつ知識をすなおに表現でき(安西,1989)、それをさらに発展させていけるものとして、知識の発見に重要な役割を担っている。
評価基準の例として、結合ルール(Agrawal, Imielinski and Swami,1993)におけるコンフィデンスとサポートを取り上げてみよう。結合ルール(association rule)とはある条件がAのとき、ある現象Bが起こることを指す。例えば、チーズバーガーを購入した顧客はアップルパイも購入する確率が高い、30代の女性にはオムツを100個以上買う人が多い、などのようなパターンやルールである。こうしたパターンやルールの確からしさをはかる評価基準にコンフィデンスとサポートがある。コンフィデンス(confidence)とは条件Aを満たすデータが現象Bを引き起こす割合を指す。コンフィデンスを見ることによって、そのパターンが起こる確からしさを評価することができる。しかし、確からしいパターンを発見しても、それがすぐに重要なパターンと考えることができない。なぜなら、条件Aを満たすデータが全体の内のわずかな部分にすぎないこともあるからだ。サポート(support)とは全データにおいて、条件Aを満たす現象Bの占める割合を指しており、これによって発見されたパターンの全体に占める重要性を評価することができる。