新規顧客からのロイヤルカスタマーの早期発見
-Discovery the Loyal Customers in Future from Newcomers-
矢田研究室
Yada Lab
大阪産業大学経営学部
Department of Business Administration, Osaka Sangyo University
Abstract
The discovery of Loyal Customers at early stage is extremely
important in highly competitive market. Loyal Customers have been
categorized in the conventional approach by measuring sales volume or sales
quantity for a certain period. However, such approach is not effective
enough to discover Loyal Customers with high probability at early stage.
The purpose of this paper is to find an effective and reliable rule for
the discovery Loyal Customers from newcomers at early stage with higher
confidence, using one of data mining tools, C 5. 0.
1 はじめに
競争環境が悪化し、長期にわたる価格競争の結果、多くの企業が疲弊している。そのような状況下、小売店やメーカーは、サービスや品質を武器に顧客にアピールし、価格以外の要素に高い付加価値を払ってくれ、自社の製品やサービスを選択してくれる「ロイヤルカスタマー」に注目している。「ロイヤルカスタマー」は提供する製品に対して高い付加価値を払うだけでなく、長期にわたってその製品を購入しつづけることから、長期間の利益を企業にもたらすものである
[1,2]。したがって、多くの企業でこうした「ロイヤルカスタマー」を獲得することは重要な問題と考えられている。
本研究では、小売店から見たロイヤルカスタマーに分析の焦点を置いている。本稿で用いられる「ロイヤルカスタマー」とは、ある店舗に対して、継続的に利益をもたらしてくれる顧客のことを指す。本研究の目的は、新規顧客の中から将来(数ヶ月、もしくは1、2年後)、ロイヤルカスタマーになる顧客を、新規来店時から2ヶ月、もしくは3ヶ月という短期間に、高い確率で予測することである。もし、こうした予測が可能になれば、より早い段階で新規顧客に対して「ロイヤルカスタマー」並みのサービスを提供することができ、その店への顧客の定着率に貢献できるものと考えられる。
C5.0を使った分析の結果、短期間で、しかも高い確率で予測することが可能であることが明らかになった。従来の現場で「ロイヤルカスタマー」は、多くの場合、ある期間の累積の販売金額や粗利で把握しようとしてきた。C5.0を使った本稿の分析では、新規来店時から3ヶ月以内の顧客の購買履歴に基づいた予測は、従来のやり方よりも高い確率で「ロイヤルカスタマー」を発見することができた。また、分析では2ヶ月の購買履歴での予測も行っており、2ヶ月以内の予測も可能性があることを示している。
本研究で用いられたデータは、関西に本部を置く、G&Gファルマ株式会社の協力を得て、いただいた関西の薬局・薬店120店舗のデータである。実際に分析に用いた該当年度の新規来店顧客の購買データは、約320万レコードである。
2 「ロイヤルカスタマー」とは何か
2-1 「ロイヤルカスタマー」の定義
「ロイヤルカスタマー」は、さまざまなアプローチから定義が可能であるが、今回は、店舗から見た「ロイヤルカスタマー」を対象にしている。我々は「ロイヤルカスタマー」を、「ある店舗に対して、継続的に利益をもたらしてくれる顧客」として定義する。
ある店舗から見た「ロイヤルカスタマー」は、その店舗に利益をもたらしてくれなければならない。価格を唯一の基準にして商品を購入する顧客は、セール商品を多く購入するため、粗利がマイナスになる。こうした顧客は、その店にロイヤリティを持っているわけではなく、価格訴求に対してロイヤリティを持っているといえる。品質やサービスなど、さまざまな効用の組み合わせで、その店を判断し、それに対する付加価値を払う顧客でなければ、店舗がさまざまなサービスを行う意味がない。したがって、利益をもたらす顧客を測定するために、我々は販売金額ではなく、粗利金額を第一の基準として採用した。
粗利金額を基準の1つとして採用するアプローチは、従来にも用いられてきた。ある一定期間の販売金額の累積や粗利の累積を基準にして、「ロイヤルカスタマー」を認識してきたのである。しかし、こうした枠組みだけで「ロイヤルカスタマー」を理解しようとすると、現実の分析では問題が出てくる。例えば新規来店時に多くの商品を購入し、その後、まったく来店しなかった顧客も半年や1年で見ると、「ロイヤルカスタマー」に分類されてしまうことになる。日本語でよい客のことを「常連」や「なじみ」と表現するように、その店にとって重要なことは1時期のみの購入ではなく、継続的な購入である。したがって我々は、継続的な購入を「ロイヤルカスタマー」を認識する第二の基準として採用した。
2-2 顧客の分類
次に上記の2つの基準に基づいて、実際に顧客の購買パターンを分類し、この分析の対象とする「ロイヤルカスタマー」を明らかにする。分析対象者は、関西120店舗の1996年1月から1998年2月の新規来店顧客、約12万人である。
事前の分析、現場での経験から、新規来店時から6ヶ月あれば、その顧客が「ロイヤルカスタマー」になるかどうかを判断できることが、従来からわかっている。まず、その6ヶ月内に継続して来店しているかを判断するために、2ヶ月の3期間に分けた。顧客の平均来店間隔日数は、39日であり、1期間(2ヶ月)の間に最低1度は来店すると考え、その3期間で顧客がどのような購買行為を行っているかを評価することにした。
次に、それぞれの顧客が店舗にどの程度利益をもたらしているかを期間内(2ヶ月間)の粗利金額の累積で次のように評価し、分類した。2ヶ月間の顧客の平均累積粗利が約1000円であることから、平均1001円以上の累積粗利を落としている顧客、買ってはいるが平均以下の1-1000円の顧客、セール商品ばかりを購入している累積粗利がマイナスの顧客、まったく来店せず粗利が0の顧客の4つに顧客を分類した。(表1)
表1 累積粗利金額による分類
|
累積粗利金額
|
粗利分類
|
|
1001円以上
|
4
|
|
1円以上1000円以下
|
3
|
|
0円以下
|
2
|
|
来店なし
|
1
|
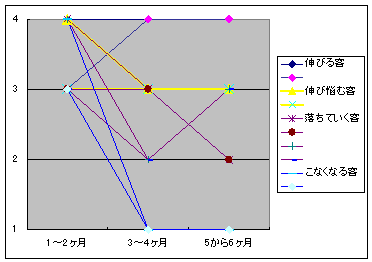
最後に、我々が考える「ロイヤルカスタマー」を明示するため、上記の2つの次元を元に、表2のような顧客分類を作り出した。最初の2ヶ月間に粗利がマイナスの顧客は、その後もほとんどが利益に貢献しないため、最初の2ヶ月に粗利がプラスの顧客、つまり表1の3か4に分類される顧客を分析対象にした。そして、次の2ヶ月間と最後の2ヶ月間に平均以上の粗利を落とす顧客(粗利分類4)を「伸びる顧客」とした。また、2、3期間のどちらかが、粗利分類3に属していた顧客を「伸びそうな顧客」、2、3期間が平均以下の粗利を上げている顧客(粗利分類3)を「伸び悩む顧客」、2、3期間のどちらか、もしくは両方で粗利金額がマイナス(粗利分類2)になる顧客を「落ちていく顧客」、2、3期間でこなくなる顧客(粗利分類1)を「こなくなる顧客」とした。分析期間の新規来店顧客のうち、これらのカテゴリーに分類される顧客は65000人であった。本稿では、このうち、「伸びる顧客」8500人をロイヤルカスタマーとした。「伸びる顧客」はその後の1年間の購買履歴を分析すると、販売金額、粗利金額、来店回数、すべてにおいて上位に位置しており、こうした「ロイヤルカスタマー」を早期に発見することが、現実に重要であると考えたからである。本研究の目的は、この「伸びる顧客」を新規来店時から2もしくは3ヶ月内に、高い確率で予測できるルールを発見することである。
表2 顧客の分類
3 C5.0によるロイヤルカスタマーのルール抽出
3-1 今回用いた属性と従来の手法の評価
今回の分析で用いた属性は、大きく2つに分けられる。顧客の購買パターンに関する属性と、購入された商品群に関する属性である。購買パターンに関する属性は、平均来店間隔日数、販売数量、販売種類(商品コードを基準)を採用した。「なじみ」になる顧客は、多くの商品を購入したり、頻繁に来店したりといった、購入パターンに特徴がある。そうした特長を計る最も典型的な数値がこれらの属性である。なお、結果属性の一部に粗利金額が利用されているため、粗利金額は属性として今回は採用していない。
また、購入された商品群に関する属性は、主に効能2桁と呼ばれる商品分類を利用し、ベビー用品、医薬品、化粧品、歯磨きの商品群の購入数量を属性として採用した。顧客がその店舗に足を運び、その店に信頼を抱くようになって初めて、「なじみ」の客になる。そうした信頼・安心を抱くことを示しそうな商品群として、上記の商品群を選び、その購入数量を属性とした。
本研究では、ルール抽出のためにC5.0というツールを利用するが、抽出されたルールの精度を比較するため、従来用いられてきた手法として、累積の粗利金額で「ロイヤルカスタマー」を判断する方法を取り上げた。上記のカテゴリーに分類された顧客65000人のうち、「ロイヤルカスタマー」つまり「伸びる顧客」は8500人であったが、従来の手法で、3ヶ月間のデータだけで予測すると、そのうち4600人、54.12%の確率で「伸びる顧客」を予測できることがわかった。
3-2 C5.0によるルール抽出
C5.0は、J. R. Quinlanによって開発されたシステムで、事例集合を決定木、プロダクションルールとして記述する分類モデルを生成するシステムである
[3,4]。まず、3ヶ月のデータで「伸びる顧客」を予測した。属性は、上記の属性に関して、新規来店時から3ヶ月間の数値を計算した7属性である。生成された分類モデルでは、65000人のうち、7852人を「伸びる顧客」と分類するルール集合を抽出した。ルール数は208で、その中で実際に「伸びる顧客」は5575人lで、予測確率は71.00%であった。これは、3ヶ月間の累積粗利より、予測精度が上がっており、C5.0を用いて3ヶ月でかなりの予測精度があることがわかった。トレーニングデータは、上記にあるとおり、96年から98年2月までの新規顧客であるが、ルールの普遍性を検証するために、98年3月から99年2月までの新規顧客2万人をテストデータにして、得られたルールの検証を行った。それによると、オーバーフィッティングで、かなり予測確率が落ちていることがわかる。また、「伸びる顧客」とその他の顧客という2分類でこの予測を行ったところ、75.89%と、高い予測確率を得ることができた。こちらの方の、オーバーフィッティングによる予測確率の低下は、10%程度であった。
さらに、より早く「ロイヤルカスタマー」を抽出するために、2ヶ月間での予測を試みた。ターゲット変数を4分類でおいて、抽出した「伸びる顧客」のルールに該当するのは7495人、その中で実際の「伸びる顧客」は4783人、予測確率は63.22%、2ヶ月での予測でも、従来の手法よりは精度が高いことがわかる。「伸びる顧客」を抽出したルール数は、66であった。また、2分類では、予測確率が73.87%で、テストデータでの予測確率も63.96%と、かなり高い数値を示した。表3は、これらの分析を比較したものである。
表3 従来の手法との比較
上記の分析では、2、3ヶ月において、かなり高い精度で「伸びる顧客」を予測することが可能であることがわかった。しかし、「伸びる顧客」を抽出するルール数が非常に多く、ルールの意味解釈が困難であり、現実への適用への不安を残すことになった。
3-3 問題点
我々は、分析の中で、現実への適用のための多くの問題点を発見した。例えば、C5.0では、分類モデルの予測確率は高いことがわかるが、抽出するためのルール数が非常に多い。また、そのルール自体も複雑で、これでは、現場の人間は、そのルールの意味を解釈することができない
[5]。それに、今回は時間の制約から限られた属性しか、分析にかけることができなかったが、もっと現場の経験から得られるような属性を分析に取り込む必要があろう。
4 おわりに
本研究では、新規顧客から「ロイヤルカスタマー」を以下に早い段階で、しかも高い確率で予測するかについて、分析を行ってきた。C5.0を用いた分析では、従来の方法よりも、3ヶ月の段階で、しかもかなり高い確率で「ロイヤルカスタマー」を予測することができた。今回の分析で用いた属性は、ターゲット属性で粗利金額を一部利用しているため、粗利金額や販売金額を使わなかった。
しかし、多くの問題も残っている。実際の計算時間がかかりすぎている点、属性の選択が十分ではない、などである。今後、こうした問題に対して取り組み、現実への適用に近づいていきたい。
参考文献
[1] D. Peppers and M. Rogers: The One to One Future, Doubleday, New York
(1993).
[2] D. A. Aaker: Building Strong Brands, The Free Press, New York (1996).
[3] J. R. Quinlan: Induction of Decision Trees, Machine Learning 1,
pp.81-106 (1986).
[4] J. R. Quinlan: C4.5: Programs for Machine Learning, Morgan Kaufman
(1993).
[5] 羽室行信: データマイニングケース研究 ―顧客販売データを用いた知識発見―,大阪産業大学論集社会科学編
108, pp.249-269 (1998).